首页 > 面试资料 博客日记
XRPC:一个能写进简历的 C++ 高性能分布式 RPC 框架,QPS 13万+
2026-05-15 16:00:03面试资料围观50次
大家好,我是小康。
先说一个让很多人沉默的问题
你在简历上写过"熟悉 RPC 框架"吗?
如果面试官接着问:"RPC 调用的完整链路是什么?从客户端发起请求,到服务端返回响应,中间每一步发生了什么?"
能流畅回答的人,大概不到 10%。
能进一步回答"连接池为什么能把 P99 延迟从 10ms 压到 0.2ms"的人,更是凤毛麟角。
这不是他们不努力,而是他们用的学习路径从一开始就走偏了——调过 gRPC,改过 GitHub 上别人的 RPC demo,但从来没有亲手造过一个。
今天这篇文章,就是为想造一个的人写的。
为什么不直接学 gRPC / brpc / srpc?
这个问题我被问过很多次,答案很直接。
gRPC 的核心 C++ 实现超过 50 万行。brpc 也在 10 万行 以上。你打开任何一个文件,迎接你的是层层宏定义、平台兼容代码、协议扩展点……光理清模块依赖关系就要花一周。
更关键的是:这些项目展示的是一个经历了多年打磨的成品。
你看不到 RpcChannel 的异步调用链是怎么一步步设计出来的,看不到 protobuf 反射 dispatch 是在哪个阶段接进去的,看不到连接池的 acquire/release 接口为什么要这样设计,更看不到 msgid 透传是怎么从协议层一路贯穿到链路追踪的。
这些"从0到1"的过程,是任何成品代码都给不了你的东西。
XRPC:4700 行,25 天,从空文件夹到完整 RPC 框架
这个项目叫 XRPC,基于我之前实现的 ReactorX 事件驱动引擎和 NetCore 网络库,向上构建完整的 RPC 框架层。
核心代码 4700+ 行,含测试与压测代码总计约 8600 行,25 天完整教学,每天增量实现,每天结束都能编译运行。
先看架构全貌:
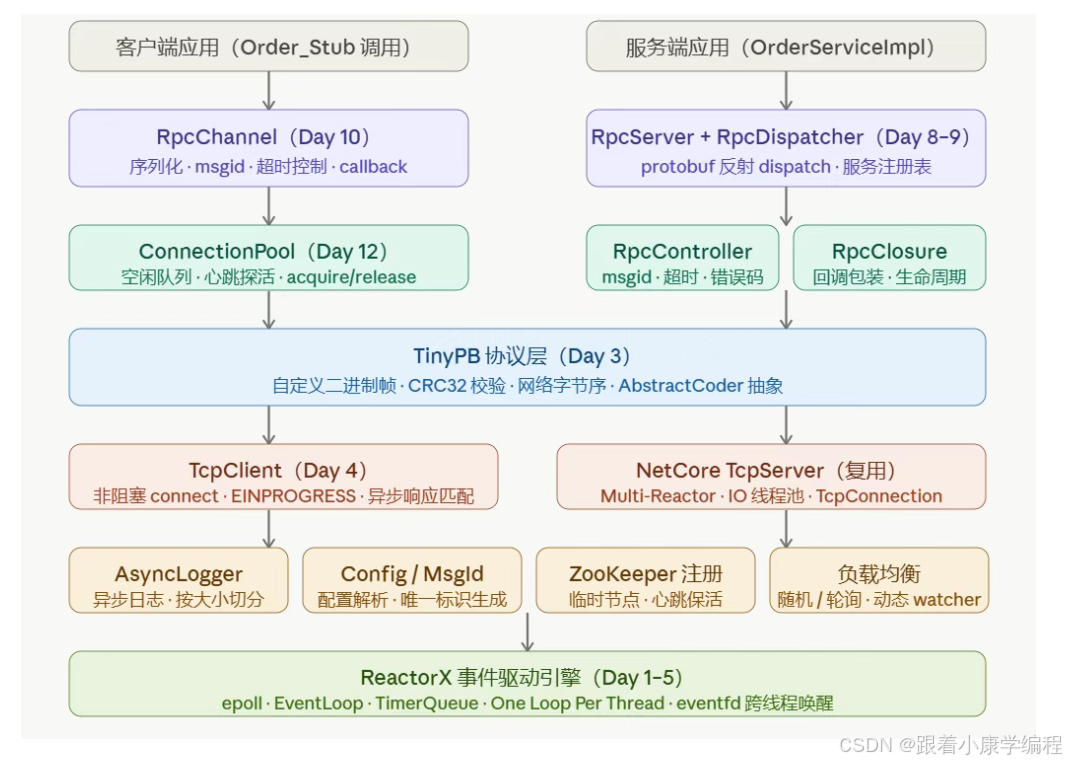
先看压测数据
同一台机器,连接池开启,1000 次顺序 RPC 调用:
P50 延迟: 0.061 ms
P95 延迟: 0.163 ms
P99 延迟: 0.226 ms ← 不到 0.23ms
最大延迟: 0.357 ms
顺序 QPS: 12,821 次/秒
延迟分布:
<0.1ms ████████████████████████████████████ 821次 (82.1%)
<0.2ms ███████ 162次 (16.2%)
<0.3ms 13次 (1.3%)
扩展性曲线,连接池开启 vs 关闭,并发 32 workers:
并发数 │ 无连接池 QPS P99 │ 有连接池 QPS P99 加速比
────────┼────────────────────────┼───────────────────────────────
1 │ 2,564 1.02ms │ 12,500 0.20ms 4.9x
4 │ 7,692 8.62ms │ 50,000 0.20ms 6.5x
16 │ 12,698 10.18ms │ 123,077 0.21ms 9.7x
32 │ 17,778 7.28ms │ 133,333 0.46ms 7.5x
连接池开启,32 并发时 QPS 达到 13.3 万,P99 仍在 0.5ms 以内。
没有连接池的版本,P99 高达 7~10ms,这就是每次 RPC 新建 TCP 连接的代价——每次都要经历三次握手,在高并发下彻底成为瓶颈。这个对比,是 Day 12 压测专题的核心内容,数据是真实跑出来的,不是估算。
三行启动服务端,五行发起调用
接口设计参考 gRPC 风格,学完之后切换任何主流 RPC 框架几乎无缝衔接:
// ══ 第一步:实现业务方法 ══════════════════════════════
class OrderServiceImpl : public order::Order {
public:
void makeOrder(google::protobuf::RpcController*,
const order::MakeOrderRequest* req,
order::MakeOrderResponse* rsp,
google::protobuf::Closure* done) override {
rsp->set_order_id("ORD-" + std::to_string(++seq_));
rsp->set_total_amount(req->quantity() * 99.0);
rsp->set_ret_code(0);
done->Run(); // 框架在此编码响应并回包
}
private:
std::atomic<int> seq_{1000};
};
// ══ 第二步:3 行启动 RpcServer ═══════════════════════
EventLoop loop;
RpcServer server(&loop, InetAddress(9090), /*io_threads=*/4);
server.registerService(std::make_shared<OrderServiceImpl>());
server.start();
loop.loop();
// ══ 第三步:客户端异步调用 ══════════════════════════
auto ctrl = std::make_shared<RpcController>();
ctrl->SetTimeout(3000); // per-call 超时 3s
auto closure = std::make_shared<RpcClosure>([&]() {
printf("订单号: %s 金额: %.2f 元\n",
rsp->order_id().c_str(), rsp->total_amount());
});
auto channel = std::make_shared<RpcChannel>(
&client_loop, InetAddress("127.0.0.1", 9090));
channel->Init(ctrl, req, rsp, closure);
order::Order_Stub stub(channel.get());
stub.makeOrder(ctrl.get(), req.get(), rsp.get(), closure.get());
// ══ 进阶:连接池(零额外代码切换)══════════════════
ConnectionPool pool(InetAddress("127.0.0.1", 9090), /*pool_size=*/8);
pool.start();
auto channel = std::make_shared<RpcChannel>(&pool); // 只改这一行
// 其余调用代码完全相同,框架自动取用空闲连接并归还
从无池切换到有池,只需改一行——RpcChannel 的构造参数从 EventLoop+地址 换成 ConnectionPool,其余调用代码一字不改。
25 天,你会亲手构建什么
整个教程分三个递进阶段,每一阶段结束都有完整可运行的交付物。
第一阶段:ReactorX 事件驱动引擎(Day 1–5)
一切性能的根基。
- Day 1 实现 epoll 封装(Poller)和事件分发抽象(Channel),第一次运行时你会看到键盘输入被事件循环捕获——这是事件驱动从概念变成代码的一刻
- Day 2 构建 EventLoop,实现 One Loop Per Thread 框架,到这天结束你已经能写一个真正跑起来的 echo server
- Day 3 接入基于 timerfd 的定时器
- Day 4 实现 eventfd 跨线程唤醒和线程池
- Day 5 做压测,QPS 可达 50 万+
第二阶段:NetCore 高性能网络库(Day 6–10)
在事件驱动引擎之上,搭建完整的网络抽象层。
- Day 6 封装 Socket RAII
- Day 7 实现 Acceptor 连接接受器(含 idleFd 技巧防止 fd 耗尽)
- Day 8 实现三区域自动扩容 Buffer(readv 系统调用一次读取所有数据)
- Day 9 是整个网络库最难也最精华的一天——TcpConnection 的四状态机、
shared_ptr + weak_ptr + tie机制防止野指针和提前析构、高水位回调控制发送缓冲 - Day 10 把所有组件粘合成 Multi-Reactor 架构的 TcpServer,主 Reactor 只接连接,Sub Reactor 池负责 IO,Round-Robin 负载均衡,三十行代码启动支持数万并发的多线程服务器
第三阶段:RocketRPC 框架层(Day 11–25)
这才是今天的核心。
Day 11:项目骨架 + protobuf 入门
CMake 工程配置,第一个 .proto 文件,protoc 代码生成流程,用 NetCore TcpServer 验证接口。很多人卡在这里——不知道 protobuf 生成的代码是怎么跟框架连接起来的。这天讲清楚。
Day 12–13:协议抽象层 + TinyPB 编解码
Day 12 实现 AbstractProtocol 和 AbstractCoder 抽象层,用开闭原则讲清楚为什么要有这一层——协议可以换,上层框架代码一行不改。Day 13 是课程第一个硬核技术点:TinyPB 二进制帧格式逐字节讲解,查表法 CRC32 真实实现(对比 rocket 原版硬编码为 1 的"假校验"),网络字节序处理,encode/decode 完整实现。
Day 14:TcpClient 实现
NetCore 原生没有客户端组件,这是本项目新增的。非阻塞 connect 的 EINPROGRESS 处理(很多人在这里踩坑),基于 map<msg_id, callback> 的异步响应匹配——这是 RPC 客户端能做到"发出请求、回调通知"的底层机制。
Day 15:异步日志系统
独立线程写磁盘,sem_t + 条件变量驱动,framework log 与 app log 分离设计,日志文件按大小自动切分。为什么要在框架层之前先做日志?因为后面每一个模块出了问题,你都需要它。
Day 16:错误码 + msgid + 配置系统
pid + 时间戳 + 原子计数器生成全局唯一 msgid,这是跨服务链路追踪的基础。配置文件驱动端口、线程数、日志级别,不再硬编码。
Day 17:RpcController + RpcClosure
protobuf 四件套(Service / RpcChannel / RpcController / Closure)的关系从这天开始清晰起来。RpcController 携带 msgid、超时、错误码,RpcClosure 包装 std::function 回调。对比 rocket 原版的裸指针,说明 shared_ptr 在这里为什么是必要的,不是风格偏好,是生命周期问题。
Day 18:RpcDispatcher(本课程最精华的一天)
protobuf 反射 dispatch 逐行拆解:FindMethodByName → GetRequestPrototype → ParseFromString → CallMethod → SerializeToString。五个调用,串起了从"收到一个字节流"到"业务方法被调用"的完整路径。看懂这一天,你就真正理解了 gRPC 的 dispatch 机制是怎么回事。
Day 19:RpcServer(服务端整合)
messageCallback 接入 TinyPBCoder decode,解码后进 RpcDispatcher,dispatch 完成后 encode + send。配置文件驱动启动流程。
Day 20:RpcChannel(客户端异步调用链)
CallMethod 的完整路径:序列化 → connect → writeMessage → readMessage → 反序列化 → closure 回调。per-call 超时控制用 EventLoop.runAfter 触发取消,shared_from_this 保证异步回调时对象还活着。RpcChannel 使用独立的 client_loop,与服务端 EventLoop 完全隔离——这个设计决策在文档里说清楚为什么这样做。
Day 21:端到端联调(第一个完整 RPC 调用)
OrderImpl 上线,客户端 Order_Stub 发起 makeOrder,std::promise/future 封装同步调用接口,端到端跑通。这是整个课程的第二个里程碑时刻——你第一次看到自己写的 RPC 框架完成一次真实调用。
Day 22:ConnectionPool(连接池 + 性能对比)
演示无池版本每次 RPC 新建连接的开销,然后实现连接池:空闲队列 + mutex + 条件变量,acquire/release 接口,心跳探活剔除失效连接,RpcChannel 改造接入连接池。压测数据就是上面那张表——从 P99 10ms 压到 0.2ms,QPS 从 1.2 万涨到 13.3 万,同一套业务代码,只换了连接池。
Day 23:ZooKeeper 服务注册 + 心跳
IP 硬编码的问题在这天被彻底解决。ZooKeeper 临时节点即心跳——session 断开,节点自动消失,天然的存活检测。服务启动后注册 /rpc/ServiceName/ip:port,无需额外心跳线程。
Day 24:服务发现 + 负载均衡
客户端从 ZK 读子节点获取可用地址,watcher 动态更新,随机/轮询两种策略可配置。两个 OrderService 实例 + 一个客户端,演示请求被自动分发到不同节点。
Day 25(加餐):综合压测专题
P50/P95/P99/P100 延迟分布直方图,QPS 随并发数的扩展性曲线(workers 1→32,无池 vs 有池),服务端 IO 线程数对吞吐的影响(io_threads = 0/2/4)。这天的数据,是你向别人介绍这个项目时最有说服力的部分。
与开源 RPC 项目的关键差异
很多人学 RPC,要么啃工业级开源项目(几万到几十万行代码,看不懂),要么找 GitHub 上的"简化版 demo"(代码量少,但问题也不少)。这些项目有一个共同特点:你拿到的是别人的成品,不是"造出来的过程"。
XRPC 不一样的地方在于:
| 对比点 | 网上常见 RPC demo | XRPC |
|---|---|---|
| CRC32 校验 | 硬编码或跳过 | 真实查表法实现 |
| 连接池 | 无,每次新建连接 | 完整实现,P99 从 10ms 压到 0.2ms |
| 内存管理 | 裸指针为主 | 全程 shared_ptr,无内存泄漏 |
| 调用方式 | 仅异步 callback | 异步 + future 同步封装两种 |
| 服务发现 | 配置文件写死地址 | ZooKeeper 真实注册与动态发现 |
| 教学文档 | 无或极简 | 25 天逐日详解,每个决策讲清"为什么" |
| 代码来源 | 改自开源项目 | 小康本人从空文件夹原创实现 |
每一个差异背后都有教学价值——CRC32 的真假让你理解校验的意义,连接池的有无让你感受 TCP 握手的代价,ZooKeeper 临时节点让你理解心跳的本质。这些不是功能点的堆砌,是课程设计刻意选择的教学场景。
学完能带走什么
一个能写进简历的完整项目。 4700 行核心代码,含测试共 8600 行,压测数据完整,面试时从协议帧格式讲到 protobuf 反射 dispatch,从连接池设计讲到服务发现的 watcher 机制,每个细节你都经手过。
对 RPC 框架的完整认知。 从协议帧的每一个字节,到 msgid 怎么穿越整个调用链,到连接池的 acquire/release 什么时候会死锁,到 ZooKeeper 临时节点为什么天然等价于心跳——这些认知,只有自己实现过一遍才会有。
一套可以继续扩展的基础设施。 ReactorX → NetCore → XRPC 这条技术链路,往上可以加 HTTP 服务器、WebSocket、分布式 KV,每一个上层项目都站在你已经写出来的底层之上,而不是又一次从零开始。
适合谁
有 C++ 基础,想真正弄懂 RPC 框架底层的开发者。对网络编程、系统设计、分布式基础有兴趣的同学。简历上缺乏有深度项目经验的应届生和工作几年的工程师——尤其是那些会用 gRPC 但说不清楚 dispatch 机制的人。
定价与报名
XRPC 完整版(Day 1–25):999 元
你将获得:
- XRPC 全部源码(4700+ 行核心代码 + 测试共 8600 行,含详细注释)
- 25 天逐日教学文档(设计思路 + 实现步骤)
- 完整压测脚本与基准数据
- CMake 构建配置,开箱即编译
- 专属答疑群(我本人亲自答疑)
搜索 jkfwdkf,备注「XRPC」,确认后付款即可当天进群获取全部资料。
更多 C/C++ 项目课程
过去 10 个月,我陆续完成了 23 个 C/C++ 硬核项目课程——从线程池、内存池、协程库,到 LSM 存储引擎、FlashHTTP-Server、Mini-Redis、Mini-STL、高性能内存分配器……想系统补齐项目经验、丰富简历、提升面试可聊内容,可以点击下面这 2 篇查看完整介绍:
为什么同样是"学过C++",有人面试碾压,有人开口就怂?差距在这18个C++硬核项目
或者直接扫码加我微信:

C++项目实战课程海报:

最后说一句真心话。
写三年 C++ 后端,调过各种 RPC 框架,但从没造过一个——这件事我见过太多人。
不是能力问题,是从来没人带着你把这条路走完过。
我已经走完了,25 天,每一天都记录下来了。
要不要跟着走一遍,你决定。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若内容造成侵权/违法违规/事实不符,请联系邮箱:jacktools123@163.com进行投诉反馈,一经查实,立即删除!
标签:
相关文章
最新发布
点击排行
本站推荐
